
This guide will cover the core features of the Wget command in Linux. Whether you’re just beginning your Linux journey or have plenty of experience, knowing how to use the Wget command can simplify your tasks. This guide will teach you how to use Wget effectively to download files, mirror websites, and manage various download tasks. Before diving into the various ways you can use Wget, let’s take a moment to understand why this command is essential in the Linux environment.
In Linux, the power of command-line tools lies in their simplicity and efficiency. The Wget command embodies this philosophy by offering a straightforward yet powerful way to handle file downloads and data retrieval. Think of Wget as your downloader—ready to fetch files from the internet with just a single command.
How to Use the Wget Command in Linux?
Wget is an incredibly versatile tool that can handle various download-related tasks. Below, we will explore the most common and useful examples of Wget usage:
Resuming Interrupted Downloads
Downloading Files in the Background
Downloading Only the HTML Page without Resources
Downloading Files Based on File Type
Recursive Download with a Depth Limit
Downloading Files with a Timeout
11 Examples of Wget Command in Linux
By learning these commands, you’ll make your Linux experience more efficient and powerful.
Basic File Download
A simple approach to using Wget involves fetching a file from the web via its URL. You can achieve this by running:
wget [URL]
Swap [URL] with the actual web address of the file you’re interested in. For example:
![wget [URL]](https://linuxworld.info/wp-content/uploads/2024/08/word-image-3965-1.png)
This command will fetch the file from the specified link and save it to your current directory.
Saving with a Different Filename
If you’d like to download a file but save it under a different name, you can use the -O option with wget. The syntax is:
wget -O [newfilename] [URL]
Replace [newfilename] with your desired file name and [URL] with the file’s web address. For example:
![wget -O [newfilename] [URL]](https://linuxworld.info/wp-content/uploads/2024/08/word-image-3965-2.png)
This command fetches the file from the provided URL and saves it as Apollo17_Plan.pdf in your current directory, instead of the original filename.
Downloading Multiple Files
When you need to download several files at once, Wget can help you do it in one go. Follow these steps to configure it:
Step 1: Prepare Your List of URLs
First, compile the URLs of all the files you want to download into a text file, say urls.txt. Every URL needs to be on a separate line:
[URL1]
[URL2]
For instance, if you want to download two files, your urls.txt might look like this:

Step 2: Use Wget to Fetch All Files
Now, use Wget to process the list and download each file:
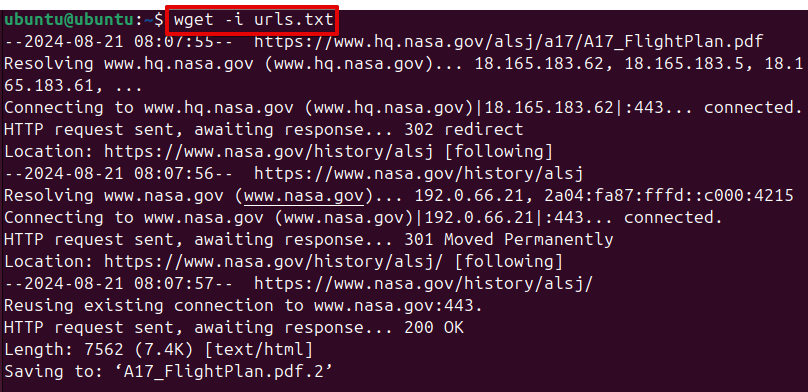
wget -i urls.txt
This command makes Wget read each URL in urls.txt and download the corresponding file, saving you the trouble of doing it manually.
Resuming Interrupted Downloads
Sometimes, downloads may get interrupted due to network issues or other reasons. Wget allows you to resume an interrupted download with the -c option:
wget -c [URL]
![wget -c [URL]](https://linuxworld.info/wp-content/uploads/2024/08/word-image-3965-5.png)
This command resumes the download of the specified file from the point it was interrupted, ensuring you don’t have to start over.
Downloading Files in the Background
You can perform a background download of a large file with the -b option.
wget -b [URL]
This command starts the download in the background, allowing you to proceed with other tasks.
![wget -b [URL]](https://linuxworld.info/wp-content/uploads/2024/08/word-image-3965-6.png)
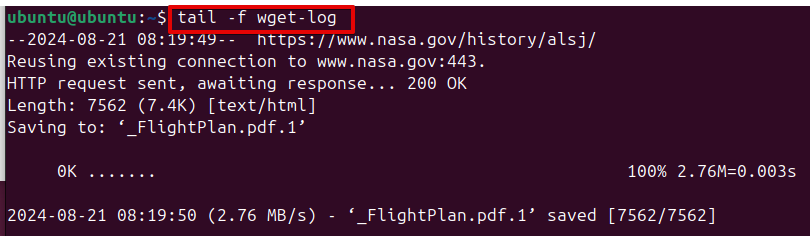
You can check the progress by reading the wget-log file:
tail -f wget-log
Limiting Download Speed
To avoid consuming all available bandwidth, Wget allows you to limit the download speed using the –limit-rate option:
wget --limit-rate=[speed] [URL]
This command limits the download speed, ensuring other network activities are not affected.
![wget --mirror -p --convert-links -P ./localdir [URL]](https://linuxworld.info/wp-content/uploads/2024/08/word-image-3965-8.png)
Downloading a Full Website
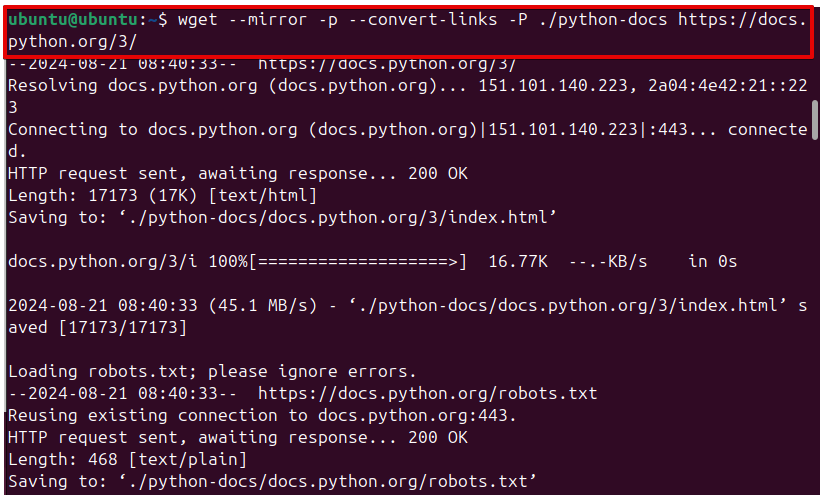
Wget can also be used to download an entire website for offline viewing. This is particularly useful for creating backups or mirroring websites:
wget --mirror -p --convert-links -P ./localdir [URL]
–mirror: Enables mirroring, which includes recursion and timestamping.
-p: Downloads all necessary files (e.g., images, CSS) to properly display the pages offline.
–convert-links: Adjust the links in the downloaded files to link to the local versions.
-P: The -P option in Wget is used to specify the directory where you want to save the downloaded files.
Downloading Only the HTML Page without Resources
If you want to download just the HTML content of a webpage without any additional resources (like images, scripts, or stylesheets), use the -N option.
wget -N [URL]
-N: Downloads the file only if it is newer than the local copy.
![wget -N [URL]](https://linuxworld.info/wp-content/uploads/2024/08/word-image-3965-10.png)
Downloading Files Based on File Type
If you need to download only specific types of files from a website, Wget allows you to filter files by extension:
wget -r -A '[file_extension]' [URL]
-r: This option allows Wget to download files from the specified URL and all its subfolders by following links.
-A ‘[file_extension]’: This option allows you to specify the accepted file types (e.g., *.jpg, *.pdf). Wget will download only those files that match the specified extension.
![wget -r -A '[file_extension]' [URL]](https://linuxworld.info/wp-content/uploads/2024/08/word-image-3965-11.png)
Recursive Download with a Depth Limit
To download a website recursively while limiting the depth of the recursion, use the -r option along with the -l option. This allows you to specify how many levels of links to follow.
wget -r -l [depth] [URL]
-r: Enables recursive downloading.
-l [depth]: Sets the recursion depth limit (e.g., 1 for one level)
![wget -r -l [depth] [URL]](https://linuxworld.info/wp-content/uploads/2024/08/word-image-3965-12.png)
This command will download the specified page and any links directly linked from that page, saving them in a directory structure that mirrors the website.
Downloading Files with a Timeout
You can set a timeout for Wget to stop trying to connect or read from a site using the –timeout option.
wget --timeout=SECONDS URL
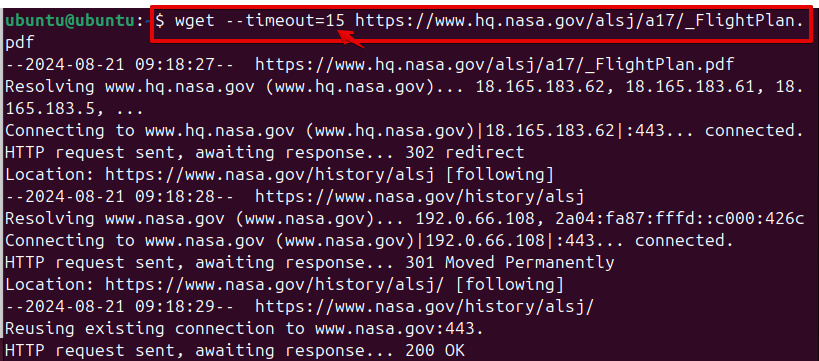
This command attempts to download the file but will stop trying if it cannot connect or read from the site within 15 seconds. This is useful for preventing hangs when the server is unresponsive.
Conclusion
This tutorial examined the Linux Wget command’s versatility and highlighted key settings for effective file downloads and data retrievals. It started with basic downloads and progressed to more advanced functionalities, such as saving files with custom names, resuming interrupted downloads, running downloads in the background, and limiting download speeds.
Additionally, the guide covered how to download entire websites, filter files by type, apply depth limits for recursive downloads, and set timeouts for improved control. By mastering these Wget options, you can streamline your downloading tasks, making it an invaluable tool for both beginners and experienced Linux users.



